先说两句
这篇博客大部分也是抄的,原文地址。
定义
哈夫曼树,又称最优树,是一类带权路径长度最短的树。首先有几个概念需要清楚:
路径和路径长度
从树中一个结点到另一个结点之间的分支构成两个结点的路径,路径上的分支数目叫做路径长度。树的路径长度是从树根到每一个结点的路径长度之和。
带权路径长度
结点的带权路径长度为从该结点到树根之间的路径长度与结点上权的乘积。树的带权路径长度为树中所有叶子结点的带权路径长度之和,通常记作WPL。
若有n个权值为w1,w2,…,wn的结点构成一棵有n个叶子结点的二叉树,则树的带权路径最小的二叉树叫做哈夫曼树或最优二叉树。
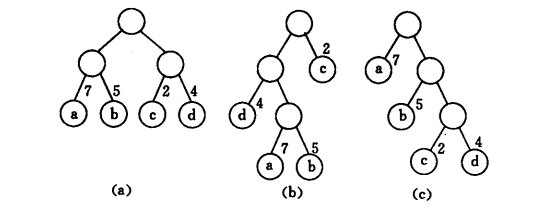
在上图中,3棵二叉树都有4个叶子结点a、b、c、d,分别带权7、5、2、4,则它们的带权路径长度为:
(a)WPL = 7×2 + 5×2 + 2×2 + 4×2 = 36
(b)WPL = 4×2 + 7×3 + 5×3 + 2×1 = 46
(c)WPL = 7×1 + 5×2 + 2×3 + 4×3 = 35
其中(c)的WPL最小,可以验证,(c)恰为哈夫曼树。
哈夫曼树的创建
假设有n个结点,n个结点的权值分别为w1,w2,…,wn,这n个结点可以看作n个只有一个树根结点的二叉树,构成的二叉树的集合为F={T1,T2,…,Tn}。基于F,可以构造一棵含有n个叶子结点的哈夫曼树,步骤如下:
- 从F中选取两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,其新的二叉树的权值为其左右子树根结点权值之和;
- 从F中删除上一步选取的两棵二叉树,将新构造的树放到F中;
- 重复第1步和第2步,直到F只含一棵树为止。
下面是一个构建哈夫曼树的例子:
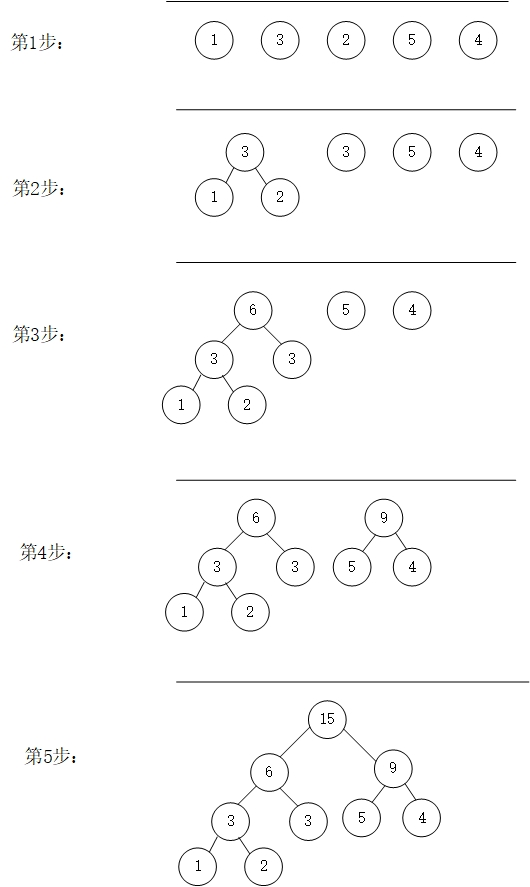
从上面的步骤可以看出,每次都需要选取F中权值最小的两个结点,原文中,大佬用了最小堆优化查找,为了让算法简单易懂(顺便偷个懒),我就直接用数组遍历查找。
创建哈夫曼树的C语言实现:
1 |
|
哈夫曼编码
我们约定左分支表示字符`0’,右分支表示字符’1’,在哈夫曼树中从根结点开始,到叶子结点的路径上分支字符组成的字符串为该叶子结点的哈夫曼编码。上面代码所创建的哈夫曼树如下所示:
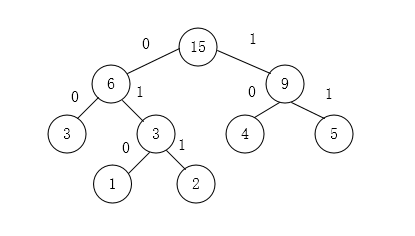
可以看出3被编码为00,1为010,2为011,4为10,5为11。在这些编码中,任何一个字符的编码均不是另一个字符编码的前缀。
输出所有哈夫曼编码的代码:
1 | /** |
