本文内容大部分抄袭引用自大佬的一篇博客。
背景
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子,具有旋转不变形和灰度值不变形等显著优点。主要用于纹理特征提取,在人脸识别部分有较好的效果。
概述
从94年T. Ojala, M.Pietikäinen, 和D. Harwood提出至今,LBP大致经历了三个版本。下面按照时间顺序进行介绍。
原始的LBP
最初的LBP算子通过定义一个3x3的窗口,以窗口内中心点的像素值为标准,对比窗口内另8个点像素值的大小,大于为1,小于为0。8个点形成一个二进制数字(通常转换为十进制表示)即为中心点的LBP特征值。详细计算如下图:
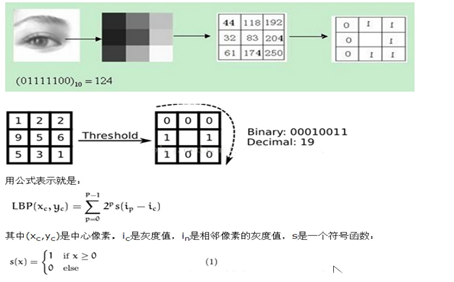
通过上面得到的LBP算子具有很多缺点,之后研究人员在LBP基础上进行不断改进。
1 | /** |
改进的LBP
原始LBP算子计算区域为像素点的周围8个点,在图像尺寸发生改变时会出现很大的偏差,不能正确反映像素点周围的纹理信息。为适应不同尺寸纹理特征,LBP原作者将圆形邻域代替正方形邻域。同时增加了旋转不变的特性,在对LBP特征值的存储部分,也进行了改进。详细如下文。
圆形LBP特征
圆形LBP特征以像素点为圆心,$R$为半径,提取半径上$P$个采样点,根据 原始的LBP 中像素值比较方法,进行像素值大小的比较,得到该点的LBP特征值。其中提取采样点的方法如下:
$$
x_t = x_d + R\cos(\frac{2\pi p}{P}) \\
y_t = y_d + R\cos(\frac{2\pi p}{P})
$$
$(x_t, y_t)$为某个采样点,$(x_d, y_d)$为邻域中心点,$p$为第p个采样点,$P$为采样点的个数。得到采样点的坐标可能为小数,改进后的LBP采用双线性插值法进行计算该点的像素值,计算公式如下:
$$
f(x, y) \approx \left[\begin{matrix}
1 - (x - \lfloor x \rfloor) & x - \lfloor x \rfloor
\end{matrix} \right] \left[\begin{matrix}
f(\lfloor x \rfloor, \lfloor y \rfloor) & f(\lfloor x \rfloor, \lfloor y \rfloor + 1) \\
f(\lfloor x \rfloor + 1, \lfloor y \rfloor) & f(\lfloor x \rfloor + 1, \lfloor y \rfloor + 1)
\end{matrix} \right] \left[\begin{matrix}
1 - (y - \lfloor y \rfloor) \\
y - \lfloor y \rfloor
\end{matrix} \right]
$$
几种不同半径不同采样点数量的LBP算子: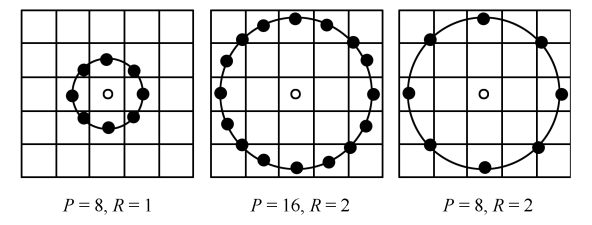
1 | /** |
旋转不变LBP特征
上面通过采取圆形邻域的计算,一定程度上削弱了尺度改变的影响。研究人员在上面的基础上进一步扩展,使具备旋转不变的特征。
首先,在确定半径大小和采样点数目后,不断旋转圆形邻域内采样点的位置,得到一系列的LBP特征值,从这些LBP特征值中选择最小的值作为LBP中心像素点的LBP特征值,具体如下图: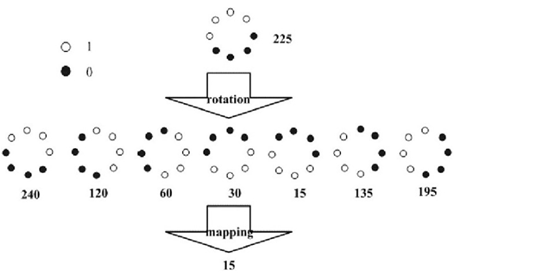
通过不断旋转,取最小值,使具备旋转不变特性。
1 | /** |
统一模式LBP特征
统一模式LBP(Uniform Pattern LBP)特征也称为等价模式或均匀模式。对LBP特征值的存储方式上,进行了优化。详细如下。
假设对于半径为$R$的圆形邻域内提取$P$个采样点,会产生$2^P$种二进制表达方法,随着邻域内采样点数目的增加,二进制模式的种类以指数形式增加,不利于LBP特征值的存储、提取、分类和识别。LBP原作者提出一种“统一模式”对LBP算子进行降维。详细如下。
在实际图像中,绝大多数LBP模式只包括从0到1或从1到0的转变,LBP原作者将“统一模式”定义为当某个LBP特征值所对应的二进制数从0到1或从1到0的转变最多有两次时,该LBP所对应的二进制就称为一个统一模式。如00000000(0次跳变)、00000011(1次跳变)、10001111(2次跳变)均为统一模式类。除统一模式类外均归为混合模式类。上述算法,使得模式数量由原来的$2^P$种减少为$P(P - 1) + 2 + 1$种($P$代表采样点的数量)。
实例介绍:
如采样点数为8,即256种LBP特征值,根据统一模式可分为59类:跳变0次——2个,跳变1次——0个,跳变2次——56个,…跳变8次——1个。(跳变1次为0个是因为LBP作者把LBP二进制数字看做一个圆性的序列,故跳变1次为0个)
1 | /** |
MB-LBP特征
MB-LBP特征,全称为Multiscale Block LBP,由中科院的研究人员研究发表,原理与HOG特征提取有相似之处,介绍MB-LBP仅用于了解,下面是原理介绍。
首先将图像分为分为多个块,再将每个小块分成多个区域,每个区域的灰度值为该区域内灰度值的平均值。在一个块内,将中心区域的灰度值大小与周围区域的灰度值大小进行比较形成LBP特征值。如下图: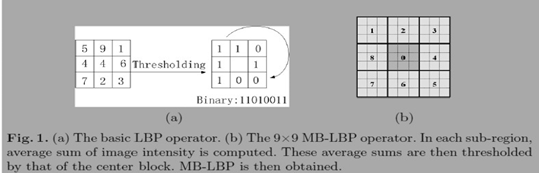
作者对得到的MB-LBP特征值同样进行均值编码。首先,对得到的特征值采用直方图进行表示,计算每一种特征值的数量,进行排序,将排序在前63为的特征值看作是统一模式类,其他的为混合模式类,共64类。
LBPH
LBP的最后一步改进为LBPH即LBP特征统计直方图的使用,可用于机器学习特征的提取。这种表示方法由Ahonen等人提出,将LBP特征图像分成m个局部块,提取每个局部块的直方图,并依次连接在一起形成LBP特征的统计直方图。具体过程如下:
- 计算图像中每一像素点的LBP特征值。
- 图像进行分成多块。(Opencv中默认将LBP特征图像分为8行8列64块区域。)
- 计算每块区域的LBP特征值的直方图,并将直方图进行归一化。(横坐标为LBP特征值的表示方式,纵坐标为数量)
- 将上面计算的每块区域特征图像的直方图按顺序依次排列成一行,形成LBP特征向量。
- 用机器学习方法对LBP特征向量进行训练。
举例说明LBPH的维度:
采样点为8个,如果用的是原始的LBP或Extended LBP特征,其LBP特征值的模式为256种,则一幅图像的LBP特征向量维度为:$64 \times 256 = 16384$维, 而如果使用统一模式LBP特征,其LBP值的模式为59种,其特征向量维度为:$64 \times 59 = 3776$维,可以看出,使用统一模式特征,其特征向量的维度大大减少, 这意味着使用机器学习方法进行学习的时间将大大减少,而性能上没有受到很大影响。
1 | /** |
